Una pregunta muy común para los iniciados en el mundo de SQL Server, es cuál es la diferencia entre un índice clustered y un índice non-clustered y en qué caso conviene usar un índice u otro. Bueno, empecemos a describir las características generales de un índice y luego de estos tipos de índices y las conclusiones van a ser evidentes.
Los índices son objetos de la bases de datos, cuya función es optimizar el acceso a datos. A medida que las tablas se van haciendo más grandes y se desea hacer consultar sobre estas tablas, los índices son indispensables.
Internamente un índice normal es una estructura de árbol, que cuenta con una página principal y luego esta con paginas hijas, que a su vez tiene más paginas hijas hasta llegar a la pagina final del índice (leaf level).
La clave del índice está repartida en las páginas del índice, de modo tal que la búsqueda se haga leyendo la menor cantidad posible de datos.
Estructura interna de un índice:
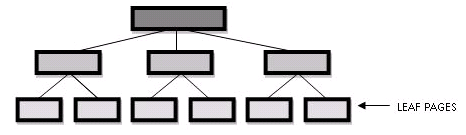
Después de esta brevísima introducción, donde está la diferencia entre un índice clustered y uno non-clustered? En la leaf level (la ultima pagina) del índice. En un índice non-clustered, la clave por la que buscamos tiene un puntero a la página de datos donde se encuentra el registro. Mientras que en índice clustered, la leaf level es la pagina de datos!. Con lo cual, el SQL Server, se ahorra hacer un salto para leer los datos del registro (Bookmark lookup). La diferencia es importante, ya que el uso de este tipo de índices al evitar tener que hacer lecturas adicionales para traer el registro, son más performantes.
Búsqueda por clustered index: |
Búsqueda por non-clustered index: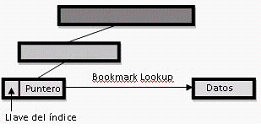 |
|
| SQL Server 2005 incorpora una nueva feature interesante en los índices non-clustered. Ahora es posible incluir dentro de la leaf page del índice, campos que en sí, no son parte de la clave. Esto nos permitirá en algunos casos, evitar el salto a la página de datos (Bookmark Lookup) que habíamos hablado anteriormente. Aunque hay que tener cuidado de seleccionar bien que campos se desean incluir al índice, porque de poner demasiados se expandería mucho el índice, haciendo ineficiente. Por ejemplo, si tenemos una tabla Personas cuyo campo DNI es un índice non-clustered y queremos hacer una consulta que solo traiga el Apellido y DNI, entonces si incluimos el campo Apellido , nos ahorraríamos tener que ir a la página de datos para buscar el valor. Es importante recalcar que el campo Apellido no sería parte de la tabla, sino un campo mas en pagina final del índice. |
Ahora bien, entonces porque no siempre usar índices clustered? Bueno, en primer lugar, lamentablemente solo puede haber 1 solo índice clustered por tabla. La razón es muy sencilla y lógica: Los registros de la tabla físicamente son las paginas leaf-level del índice clustered. Los datos de la tabla esta ordenados según el índice. Y obviamente una tabla no puede simultáneamente estar físicamente ordenada de 2 maneras diferentes.
Por lo tanto, en tablas grandes y muy consultadas, tenemos que ser cuidadosos y analizar a que campos vamos a seleccionar para ser llaves del índice clustered. Tenemos 1 solo índice de este tipo por tabla, no hay que desperdiciarlo!!!
Este último punto es importante para saber en qué situaciones y para que campos se debe utilizar un clustered index o un non-clustered.
Guía general de uso de índices:
- Campos autoincrementales (Identitys, newsequentialid, etc), deben convenientemente ser del tipo clustered index. La razón es reducir el page split (fragmentación) de la tabla.
- Los clustered index son convenientes si se va seleccionar un rango de valores, ordenar (ORDER BY) o agrupar (GROUP BY).
- La PK es un buen candidato para un clustered index. Pero no siempre. Por ejemplo, si tenemos una tabla de ventas, cuya PK es un identity en donde se efectúan muchas consultar por rangos de fecha, el campo Fecha seria un mejor candidato para el clustered que la PK.
- Para búsquedas de valores específicos, conviene utilizar un non-clustered index.
- Para índices compuestos, mejor utilizar non-clustered index (generalmente).

Muy bueno!!!
Comentarios por Nadia — agosto 2, 2008 @ 3:36 pm
Excelente aclaratoria.
Gracias.
Comentarios por Teresa — agosto 6, 2008 @ 12:45 pm
Es un artículo bastante bueno, muy muy bueno, gracias
Comentarios por Roberto — octubre 21, 2008 @ 3:45 am
que es la pK
Comentarios por vero — octubre 21, 2008 @ 6:43 pm
Es la abreviatura en inglés para calve primaria (Primary Key).
Comentarios por CACO — diciembre 28, 2010 @ 1:19 pm
calve?
Comentarios por Anónimo — junio 6, 2013 @ 9:46 pm
te leiste todo el articulo sin saber que es una pk?
Comentarios por Anónimo — junio 7, 2013 @ 1:41 pm
PK es Primary Key
Comentarios por grimpi — octubre 24, 2008 @ 12:23 pm
así es
Comentarios por Anónimo — febrero 7, 2018 @ 7:06 pm
[…] traduce como un salto a la lectura del índice clustered. Para entender mejor este punto, recomiendo leer este post que escribí hace un tiempo. En SQL Server 2000 toda esta operación es mostrada en un solo icono, mientras que […]
Pingback por Entender el Plan de Ejecución en SQL Server 2005/2008 « Grimpi IT Blog — octubre 29, 2008 @ 1:28 am
Muy buen artículo. Gracias :D
Comentarios por Leonardo — noviembre 27, 2008 @ 4:07 pm
que pendeja esta la que pregunto lo del PK… pues es POKEMON!!
Comentarios por el PK — febrero 11, 2009 @ 9:11 pm
La pregunta pendeja es aquella pregunta que no se hace :D
Comentarios por Alberto López — abril 6, 2012 @ 1:37 am
mis boloñas son las que no se hacen
Comentarios por boloñiles — May 18, 2012 @ 3:36 pm
muy buen aticulo! gracias!!
Comentarios por RetratoFolk — febrero 12, 2009 @ 9:50 pm
muy buen articulo. Gracias
Comentarios por yaima — febrero 17, 2009 @ 12:02 pm
muy buen articulo!!!!!!!!!
saludos..
Comentarios por ludim — febrero 20, 2009 @ 9:04 pm
Gracias, muy buena explicacion :D pasare mi examen de base de datos con eso jejej
Comentarios por Salvador — marzo 11, 2009 @ 8:29 pm
me aclarate la mente despejando la duda gracias
Comentarios por Jose — marzo 24, 2009 @ 6:30 pm
gracias, me ayudo muchisimo
Comentarios por Oscar — abril 8, 2009 @ 1:46 am
Gracias por la aclaracion me brindo mucha ayuda
Comentarios por yEISON — abril 17, 2009 @ 10:16 pm
muy buen articulo pero cuantos indices nonclustered soporta el SQL Server 2008???
Comentarios por TiCo — May 22, 2009 @ 1:15 am
ME ayudo mucho este artículo
Saludos.
Comentarios por ophelya — junio 1, 2009 @ 5:39 pm
Que buen artículo… excelente… gracias.
Comentarios por Mauro — junio 8, 2009 @ 1:18 am
hasta ahora no tengo bien en claro la diferencia entre clustered y nonclustered =(
Comentarios por paty — junio 23, 2009 @ 3:19 am
Muchas gracias!! Tengo un parcial mañana y esto me salvó las papas…
Comentarios por Pablo — junio 23, 2009 @ 1:49 pm
pues cambiate de carrera, ponete a vender limonada, jejejeje
Comentarios por Anónimo — agosto 8, 2013 @ 3:52 pm
En campos combinado no es aconsejable usar esta propiedad, mi consulta es: que pasa si tenes una tabla de historicos y las consultas son por varios campos en donde siempre preguntas por una fecha ademas de otros indices es conveniente hacer solo la fecha como index clustered?
Comentarios por Martin — julio 20, 2009 @ 2:22 pm
Muy buena la información.
Saludos,
Comentarios por black — octubre 16, 2009 @ 8:48 pm
ES LA EXPLICACION MAS PADRE ¡ME SALVARON DE NO SACAR 8 EN EL EXAMEN!
Comentarios por sandra paola ernandez — noviembre 1, 2009 @ 6:06 pm
Muy buen comentario y facil de entender
Comentarios por Anónimo — diciembre 19, 2009 @ 2:30 am
Excelente explicación! Gracias, me ayudo a entender mejor las diferencias entre estos tipos de indices =)
Comentarios por Gaby Galicia — diciembre 28, 2009 @ 2:33 am
Muchas gracias por este post! Felicidades.
Comentarios por student — enero 21, 2010 @ 6:52 am
Genial!
Comentarios por manuel — enero 21, 2010 @ 1:08 pm
?Porqué no lo escriben directamente en inglés? ?Para qué mantener la ilusión de que están escribiendo en español?
Comentarios por Alejandro Vilafranca — marzo 12, 2010 @ 10:37 am
Gracias por el tiempo que usaste explicando esto. Yo solo sabia que se podia usar un PRIMARY KEY o un UNIQUE. Pero la explicacion me dejo en las mismas! Seria bueno poner un ejemplo con tablas de Northwind o algo asi.
Comentarios por Noobvato — julio 26, 2010 @ 2:24 pm
Muchas gracias por la aclaración , bastante sencillo de entender gracias a el ejemplo.
Comentarios por Esteban — octubre 7, 2010 @ 7:33 pm
very good ! ! !
thank’s you . . .
Comentarios por jose antonio — noviembre 9, 2010 @ 11:13 pm
gracias mañana tengo q exponer de los indices … me ayudaste!
Comentarios por Angely — noviembre 13, 2010 @ 7:03 am
I just typed «Which is the difference between a clustered or a non clustered primary key» on Google!
You’re BIG!
Comentarios por chocolatiel — diciembre 4, 2010 @ 8:21 pm
Estupenda explicación. Gracias. Pero me surge otra duda, cuando tienes un indice normal, no tienes una «copia de la tabla», ordenada por ese índice ??
Comentarios por SARA — enero 18, 2011 @ 1:50 pm
Si llamamos «indice normal» a un indice nonclustered, entonces la respuesta es no. Simplemente tienes una estructura en forma de arbol con las columnas que seleccionaste.
Existe una forma de hacer una «copia de la tabla» que es crear un indice nonclustered por la llave que uno mas desee y seleccionar el resto de los campos como «incluidos». Pero no recomiendo esa practica en absoluto.
Comentarios por grimpi — enero 18, 2011 @ 2:40 pm
Muy buen articulo! Gracias!
Comentarios por Mauricio — marzo 4, 2011 @ 5:12 pm
Exelente articulo, muy bueno!!!!! felicitaciones al Autor
Comentarios por Hecor moran — marzo 5, 2011 @ 5:55 pm
Y mis 50 mil pesos que…
Comentarios por La Canaca — marzo 29, 2011 @ 1:33 am
Muchas gracias!!
Comentarios por Anonimo — May 3, 2011 @ 12:11 am
excelente articulo… pero me gustaria saber si nos puedes explicar los otros tipos de indices que hay , xml,filtered etc etc… gracias
Comentarios por Edwin Reyes — May 12, 2011 @ 1:08 am
Dadas las imagenes de la busqueda por un «clustered index» y la busqueda por un «non-clustered index»;
Como se veria la grafica del arbol para una busqueda en una tabla no indexada??
Comentarios por Emmanuel R.C. — May 24, 2011 @ 2:23 pm
muy buen articulo exelente
Comentarios por Anónimo — junio 16, 2011 @ 10:01 pm
Muy bueno el post, pero lo unico que le falto, fue el codigo de SQL para crear los 2 tipos de Indices. Saludos
Comentarios por Oscar — julio 13, 2011 @ 9:59 pm
gracias! muy claro
Comentarios por Anónimo — julio 26, 2011 @ 9:03 pm
Muchas, gracias buen articulo,
anexo dos ejemplos
create unique clustered index NameIndice on Tabla
(campo1,campo2,..campo-n)
create unique nonclustered index NameIndice on Tabla
(campo1,campo2,..campo-n)
Comentarios por Javier — julio 26, 2011 @ 9:28 pm
[…] de pedazo de código va a ser una tabla con el nombre del Servidor, el nombre de la Instancia, IsClustered y la versión de la Instancia. Les dejo una imagen de cómo […]
Pingback por Averiguar las instancias de SQL Server instaladas | Experiencias .NET — julio 28, 2011 @ 3:41 pm
[…] Tutorial: Diferencias entre Indices Clustered y NonClustered […]
Pingback por Guia Preparación Examen 70-433 « Santimacnet's Blog — agosto 26, 2011 @ 11:20 am
Usted es un capo mi viejo! =) Gracias por el artículo.
Comentarios por José — octubre 8, 2011 @ 1:51 pm
Uno de los mejores posts que he leido. Muy fácil de entender! Muchas gracias.
Comentarios por PP — diciembre 14, 2011 @ 2:19 am
me gusta el articulo pero creo que se veria mejor si no se usaran palabras como «mas perfomante», se deforma el español y no se habla ni ingles ni español….eso se llama pocho…ha…al fin este comentario no te sera tan performante..!!
Comentarios por Anónimo — diciembre 14, 2011 @ 8:56 pm
Gracias por la aclaracion, sigue aportado tus conocimientos, eso te hace un mejor ser humano.
Gracias
Comentarios por Luis Barrantes — febrero 13, 2012 @ 5:51 pm
Excelente artículo, por fin alguien me pudo explicar con facilidad que son los índices!
Comentarios por moibe — marzo 6, 2012 @ 8:56 am
Buena explicación! Gracias!
Comentarios por Anónimo — marzo 13, 2012 @ 1:30 pm
Excelente la explicación… mejor que mi profesora :)
Comentarios por Anónimo — julio 15, 2012 @ 2:17 pm
Grasias!!!
Comentarios por Erlin — agosto 3, 2012 @ 3:59 pm
que lindo che
Comentarios por Anónimo — septiembre 18, 2012 @ 5:22 pm
Impresionante lo claro de la explicación. Muchas gracias por el aporte
Comentarios por Beto — octubre 4, 2012 @ 4:40 pm
Gracias, muy buena explicación.
Comentarios por Anónimo — octubre 9, 2012 @ 7:41 pm
En otras palabras, un índice clustered (Agrupado) es óptimo para tablas de consultas, que no requieren ser tocadas de forma contínua. Ejemplo: Una tabla clientes perfectamente podría tener un índice clustered, ya que no andamos ingresando clientes a cada segundo. Sin embargo, una tabla encabezado_factura y detalle_factura, debería se nonclustered, ya que se insertarán muchos registros de artículos de venta durante el día, y si pensamos que son varios los puntos de venta a lo largo de todo el país, la tabla irá creciendo notablemente a cada minuto.
Un índice clustered es rápido en lectura, ya que los registros siempre están agrupados por si índice. Mientras que un índice nonclustered es rápido en transacción (Insert, Update o Delete), pero lento en lectura, ya que los registros no los agrupa por su índice.
Comentarios por Enrique — abril 1, 2013 @ 4:15 pm
Muchas gracias!! Excelente explicaciòn :D
Me ayudaste muchísimo :)
Comentarios por Alin Guadalupe Navarrete Arteaga — abril 27, 2013 @ 7:27 pm
Excellent beat ! I wish to apprentice even as
you amend your web site, how can i subscribe for a weblog site?
The account helped me a applicable deal. I were a little bit familiar of this
your broadcast provided brilliant transparent idea
Comentarios por ロレックススーパーコピー — May 16, 2013 @ 1:36 pm
Exc mucha gracias
Comentarios por Anónimo — agosto 22, 2013 @ 5:03 pm
[…] https://grimpidev.wordpress.com/2008/03/08/diferencias-entre-clustered-y-non-clustered-index-en-sql-s… […]
Pingback por Indices en SQL Server (Discriminando la versión) | sqlugica — febrero 6, 2014 @ 10:19 pm
mountto grazzie!
Comentarios por Anónimo — agosto 11, 2014 @ 5:31 pm
hola, ¿por que Microsoft SQL Server por defecto establece un indice «tableIndexStatistic» y un «tableIndexClustered» para la 1ra columna de la clave primaria? ¿que es ese indice «tableIndexStatistic»? ¿un mismo indice puede asignarse a varias columnas? Gracias por la ayuda.
Comentarios por dario90 — octubre 23, 2014 @ 6:53 pm
Simple, preciso y conciso.
Comentarios por Enrique Padilla — enero 12, 2015 @ 4:40 pm
Muy Bueno
Comentarios por Ctezo — abril 24, 2015 @ 10:54 pm
Ok cual es la diferencia de un NonCloster y un NonSecuencial?
Comentarios por Yury — junio 12, 2015 @ 11:57 pm
Excelente, muchas gracias
Comentarios por Anónimo — junio 25, 2015 @ 8:34 pm
super cool tu explicación, con esto ya entendi el tema de indices.
Comentarios por Roger — julio 9, 2016 @ 8:53 pm
Así es que estaba buscando un blog. Muchas gracias por tomar minutos de tu tiempo para enseñarnos a todos de esta manera tan extraordinaria. Muchas gracias por tu aporte, entendí muy bien el tema
Comentarios por Anónimo — septiembre 16, 2017 @ 6:06 pm
También podría servir este artículo, se hace una explicación desde otra perspectiva. Ojalá ayude.
http://dbadixit.com/indices-cluster-en-sql-server/
Comentarios por Anónimo — julio 5, 2018 @ 7:32 pm
Gracias por el artículo. Sencillo directo a la información. Muy clara la explicación. Entendido.
Tenía un problema con el STORAGE que se asigna, pues normalmente manejo un STORAGE DATOS para los datos y STORAGE INDICES para los índices, PERO, si el índice es de tipo CLUSTERED, obliga al mismo STORAGE DATOS para ese índice. Ahora le encuentro la lógica.
Comentarios por fpuyuelo — abril 22, 2019 @ 11:51 am